
Subproject C1
Robustness and Security
The project deals with the On-the-Fly scenario’s robustness and security. This includes methods for synchronization, behavior control and data management in dynamic networks. Dynamically changing cooperations also require suitable cryptographic methods - especially for authentication and for ensuring confidentiality, but also including access control -, which we will develop based on identity-based cryptography. Besides these security objectives, we also want to achieve data privacy and legal certainty for participants - leading to both technical and legal challenges.
Robust Distributed Systems
To guarantee a high availability in the OTF market, scalable and robust methods for synchronization, behavior management and data management have to be studied.
Consensus
A central problem in the field of distributed systems is the distributed consensus. In a consensus problem, the set of all processes is required to agree on a common value, out of one of the values initially held by one of the processes. If all processes are fault-tolerant and work without delays, the consensus problem can easily be solved by using a leader selection protocol. In the case of presence of faulty processes, the consensus problem becomes much harder. The problem of distributed consensus has extensively been studied in the last decades. The known protocols are usually developed with the goal of maximizing the number of allowed adversaries (faulty processors).
It is well known that any protocol that solves distributed consensus with g honest participants can tolerate at most f < g/2 faulty participants. In other words, the honest participants need a two-third majority and a simple majority (g>f) is not enough. The reason for this are the adversary's abilities to a) control all message delays in the network and b) to send different/conflicting messages to different participants. In our first line of work, we argue that these assumptions are too pessimistic for internet-scale applications. Participipants may have hidden trust relations or connections that can not controlled or even observed by a third party. For example, an honest participant can simply join with several unrelated IP adresses to confuse the adversary. Thus, the adversary can not control the flow of messages as tightly as required by classical lower bound arguments. Based on these observations, we develped a model to formalize these "hidden links" between participants. In our first contribution [1], we focussed on the case that each honest participant joins a system with k unrelated identities. We could show that maximum number of faulty players goes from g/2-1 to g(1-1/2^k) and present a protocol that almost matches this bound. Thus, for high values of k, the bound shift closer and closer to a simple majority.
Although, we could impove the number faulty participants with our additional assumptions, our protocols or, more generally, similar protocols that aim for a high number of faulty processes lead to a running time which is not acceptable for highly scalable systems. For instance, it is known that previously considered protocols for distributed consensus require on average a linear amount of time for every process, if the maximum number of possible faulty processes is allowed. Furthermore, previously presented protocols for distributed consensus usually are not self-stabilizing. Our goal is to determine up to which number of faulty processes an efficient protocol (a protocol with a maximum of polylogarithmic cost for each participant) is possible. Additionally, we aim to develop self-stabilizing protocols for the problem of distributed transactions, which are supposed to work correctly despite the presence of adversaries.
In [2] we presented a simple randomized algorithm that, with high probability, just needs O(log(m)loglog(n)+log(n)) time and work per process to arrive at an almost stable consensus for any set of m legal values as long as an adversary can corrupt the states of at most √n processes at any time. Without adversarial involvement, just O(logn) time and work is needed for a stable consensus, with high probability.
Further, we analyzed models that limit the adversaries knowledge to a more realistic level and see how this affects its power. It is known that O(√n) is a tight upper bound on the number adverserial processes if the adversary has full knowledge of the network. That means, it knows the current state of all nodes. However, full knowledge is not a very realistic assumption as an attacker would need instantanious access to every participant in the network. In [3] we assumed that the adversary has slightly outdated information about the system. In particular, we simply assume that it takes one round round to gather all information from all nodes. As it turns out, this small and realistic constraint significinatly increases the robustness of consensus protocols. With this so-called 1-late adversary the almost-everywhere consensus tolerates up to O(n) faulty processes.
[1] T. Götte, C. Scheideler "Brief Announcement: The (Limited) Power of Multiple Identities" in the 34th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2022
[2] B. Doerr, L. A. Goldberg, L. Minder, T. Sauerwald and C. Scheideler: "Stabilizing Consensus with the Power of Two Choices", in the 23rd Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2011
[3] P. Robinson, C. Scheideler, A. Setzer: "Breaking the Ω(√n) Barrier: Fast Consensus under a Late Adversary", in the 30th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2018
Robust Overlay Networks
A key requirement for distributed applications is reliable communication between all participants. The OTF Market is no excpetion to this. Suppose an attacker is able to isolate an OTF Provider from the rest of the market such that it is only connected to Service Providers selected (or even controlled) by the attacker. Then any user that directs a request to this OTF Provider will only be offered the attacker's services. These services may be overpriced, malicious, or both.
To prevent this, we research algorithms and techniques to keep the communication network connected. Therefore, we model the OTF Market as an overlay network where two nodes --- which may not be directly physically connected --- can communicate with one another using their IP addresses. On the one hand, this allows the nodes to form robust topologies by simply sharing their addresses with other nodes. On the other hand, it makes the nodes an easy target for DDoS attacks. Also, the fact that any node can forward addresses makes it hard to decide whether a node can safely leave the overlay. In the past funding period we investigated two problems in this context. First, we considered algorithms that maintain connected overlays under massive churn controlled by an adversary.
Second, we looked into solutions for the so-called Finite Depature Problem (FDP) where an adversary controls the delivery of messages. In both cases the adversary's goal is to partition the network into two or more subnetworks that cannot communicate with one another.
In the first problem, we assume an adversary that can decide which nodes join and leave the network in a given step. Such an adversary could churn out nodes at crucial points in the overlay and thus disconnect it. It is provably impossible to maintain a connected overlay if such an attacker has knows the network's topology [1]. Therefore, we considered an adversary with slightly outdated information about the network[1,2].
For example, in [2] the adversary can access all information that is at least O(log log n) rounds old, where n is minimal amount of nodes in the network. This includes the nodes' internal states, random decisions, and the content of all messages etc.Furthermore, the adversary can add and remove a constant fraction of nodes in each round. Given these restrictions we development an algorithm that maintains a connected overlay that rearranges itself every O(log log n) rounds. The core approach is constant sampling of other nodes' addresses within the overlay and switching places with them. Finally, we considered a more relaxed view of the adversary and asked ourselves, how quickly the overlay topology can be recovered after a fault/attack (assuming that no further faults/attacks occur in this time frame). In [3], we could show that it takes only O(log n) time steps to contruct typical overlay topologies starting from any initial topology. This proved the long standing conjecture that this is possible. Our algorithm relies on random sampling new connection via random walks, a technique that commonly used in practice. Thus, in addition to being fast and having optimal theoretical guarantees, it is easy to understand and implement.
In the study of the FDP problem we set a diffrent focus. Here, we consider an asynchronous scenario where the delivery of messages may be delayed and the overlay could be malformed. With this assumption is impossible to locally determine whether a node can safely leave the network without compromising the connetivity. As it turns out, this problem is indeed impossible to solve without the the use of oracles. The self-stabilizing Relay Layer proposed in [4] is a possible implementation of such an oracle. The core idea is to limit a node's capability to forward addresses and only allow a safe forwarding of addresses. Starting from almost any initial configuration the Relay Layer converges to a state where each node can safely decide whether it can safely leave the overlay. Further, the use of the Relay Layer does not weaken the overlay model as still any topology can be constructed.
[1] T. Götte, V. R. Vijayalakshmi, C. Scheideler "Always be Two Steps Ahead of Your Enemy", in the 33rd IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2019
[2] M. Drees, R. Gmyr, C. Scheideler "Churn- and DoS-resistant Overlay Networks Based on Network Reconfiguration" in the 28th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2016
[3] T. Götte, K. Hinnenthal, C. Scheideler, J. Werthmann "Time Optimal Construction of Overlays", in the 40th ACM Symposium on Principles of Distributed Computing (PODC), 2021
[4] C. Scheideler, A. Setzer: "Relays: A New Approach for the Finite DepartureProblem in Overlay Networks", in the 20th International Symposium on Stabilization, Safety,and Security of Distributed Systems (SSS), 2018
Robust Data Management
In this subarea we examined the develoopment of distributed storage systems that are provably robust against DoS attacks by so called insiders. An insider is an adversary that knows everything about the system and has the ability to use this knowledge in order to block a huge fraction of the servers by a DoS attack.
Previous works only considered past insiders, i.e. adversaries that only have knowledge about the complete system up to a specific past point t in time.
In [1] and [2] Scheideler et al. presented a distributed storage system that is able to efficiently and correctly serve lookup and write requests that were inserted or updated after the time point t despite the existence of a past insider that blocked a huge fraction of the servers by a DoS attacks.
In the first funding period we developed a distributed information system, called IRIS, that can efficiently and correctly serve lookup requests despite a running DoS attack performed by a current insider [3].
To be more precise, IRIS is able to correctly serve any set of lookup requests (with at most a constant number of requests per non-blocked server) with only polylogarithmic time and work at every server although up to a constant fraction of the servers is under a DoS attack by a current insider. In order to guarantee this our system only requires a sublogarithmic redundancy.
Our system even works with only a constant redundancy, if we reduce the maximum number of blocked servers allowed to O(n^(1/loglogn)).
Based on IRIS we developed RoBuSt, a distributed storage system that provides the ability to serve lookup and write requests even while the system is under attack by an insider.
RoBuSt tolerates a current insider that blocks up to O(n^(1/loglogn)) servers by DoS attacks and can correctly answer any set of lookup and write requests (with at most a constant number of requests per non-blocked server) with only polylogarithmic time and work at every server.
An interesting further extension of IRIS and RoBuSt would be the handling of even stronger adversaries.
As an example one could consider a current insider that corrupts the storage of servers without the servers being aware of this. Even more challenging is the consideration of current insiders that choose a huge fraction of servers to be Byzantine.
[1] B. Awerbuch and C. Scheideler: "A denial-of-service resistant DHT", in 21st International Symposium on Distributed Computing (DISC), 2007
[2] M. Baumgart, C. Scheideler and S. Schmid: "A DoS-resilient information system for dynamic data management", in the 21st ACM Symp. on Parallelism in Algorithms and Architectures (SPAA), 2009
[3] M. Eikel and C. Scheideler: "IRIS: A Robust Information System Against Insider DoS-Attacks", in Proceedings of the 25th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), 2013
[4] M. Eikel, C. Scheideler and A. Setzer: "RoBuSt: A Crash-Failure-Resistant Distributed Storage System", in Proceedings of the 18th International Conference on Principles of Distributed Systems (OPODIS), 2014
Cryptographic Solutions in an On-The-Fly Computing System
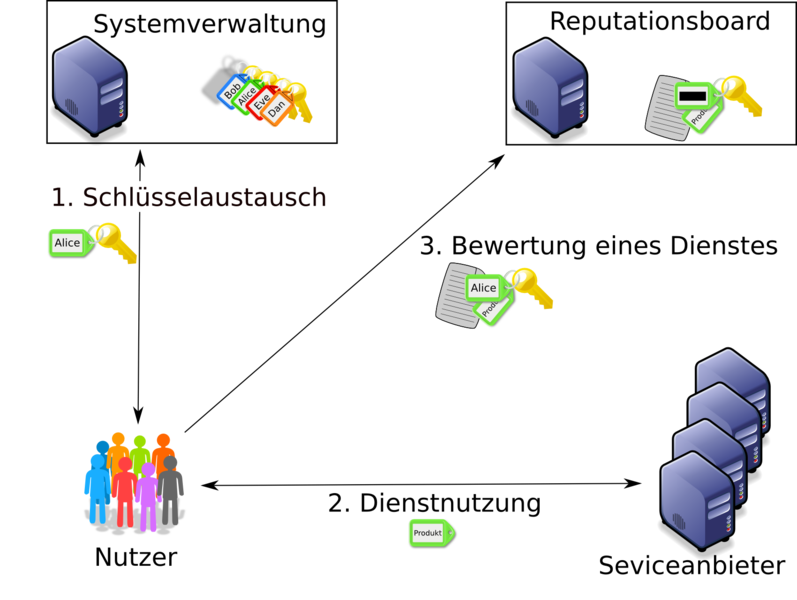
Successful marketing and acceptance of On-The-Fly Computing systems require dealing with their security. The highly dynamic and heterogeneous nature of the visioned system as well as data protection and further legal requirements pose a challenge for modern cryptography and require novel cryptographic solutions.
During the course of the project we intend to design solutions for confidential and authenticated communication in dynamic groups based on identity-based and attribute-based cryptography. This requires key revocation and reduction of power of authority for identity-based schemes. Efficient allocation of services and data access control in On-The-Fly Computing systems also require novel cryptographic schemes, which we intend to realize based on the attribute-based encryption schemes.
Another important market mechanism in On-The-Fly Computing Systems is an anonymous reputation system which enables clients to rate products and services and gives incentives to providers to improve their services. Hence, in this part of the project we develop new models of security and schemes to build a highly flexible and secure reputation system.
Anonymous Group Signatures and Reputation Systems
In standard signature schemes, the sender computes a signature on his message using his secret key. The receiver can check, using the signature and the sender's public key, that the message was indeed composed by the sender and that it was not modified in transit. To achieve this, the public key must uniquely identify the sender. However, in many scenarios this strict identification is not necessary or even desirable. Whenever an application only needs assurance that the sender belongs to a certain group of possible senders, anonymous group signatures can be used.
Anonymous group signatures allow each member of a group to sign messages without disclosing their identity. For this, each group member gets their own private key that is associated to the group's public key. In contrast to standard digital signature schemes, the message receiver can only check whether some group member signed the message, but not which specific member did it. The actual signer can only be determined by a special entity in the system (the group manager).
Besides anonymity, other properties of group signatures play an important role in some applications. For example, it may be useful to restrict the number of messages that each group member can sign. Furthermore, techniques for revoking group membership are important. In particular, these and other extensions of group signatures can be used to construct anonymous reputation systems.
Reputation systems are an important tool to allow customers and providers of goods and services to gather useful information about past transactions. In order to receive trustworthy, reliable, and honest ratings, a reputation system should guarantee the customer anonymity and at the same ensure that no customer can submit more than one rating. Of course the ratings should be publicly verifiable by third parties.
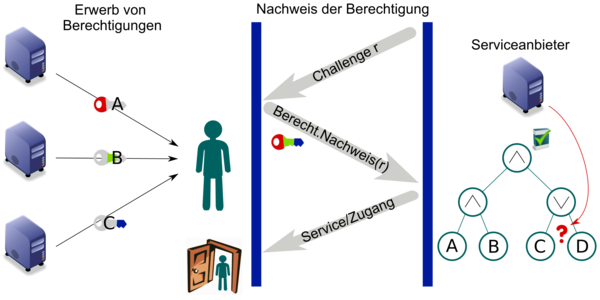
Anonymous credential systems
In anonymous credential systems, users obtain credentials that certify attributes. With a credential, a user can access certain resources or services without revealing his identity. For this, he needs to prove that he is in possession of a credential with attributes that fulfill the resource's or service's access policy. We are interested in anonymous credential systems that support complex access policies.
In order for an anonymous credential system to be considered secure, the user must be able to access a resource without revealing his identity. Besides anonymity of users, credential systems must also make sure that users cannot collude and combine their attributes. A group of users must not be able to access to a resource for which none of the users (individually) have access to. Constructions of anonymous credentials usually rely on - among others - pairings and digital signatures.
Further information: