
Subproject B1
Parameterized Service Specifications
This subproject deals with different types of requirement specifications, which enable the successful search, composition, and analysis of services. In the first phase (until June 30, 2015), the focus was on the development of a specification core language for services in order to automatically, accurately, and efficiently process the services. In the second phase (until June 30, 2019), user-friendly requirement specifications were introduced. These specifications are intuitively understandable and mainly used by the customers (i.e., end users, domain experts) on the On-the-Fly (OTF) market. The third phase (until June 30, 2023) deals with the dialog-based requirement compensation (Figure top left) and natural language service explanation (Figure top right), as deficits in requirements specifications cannot always be compensated automatically and users do not know which requirements resulted in a service.
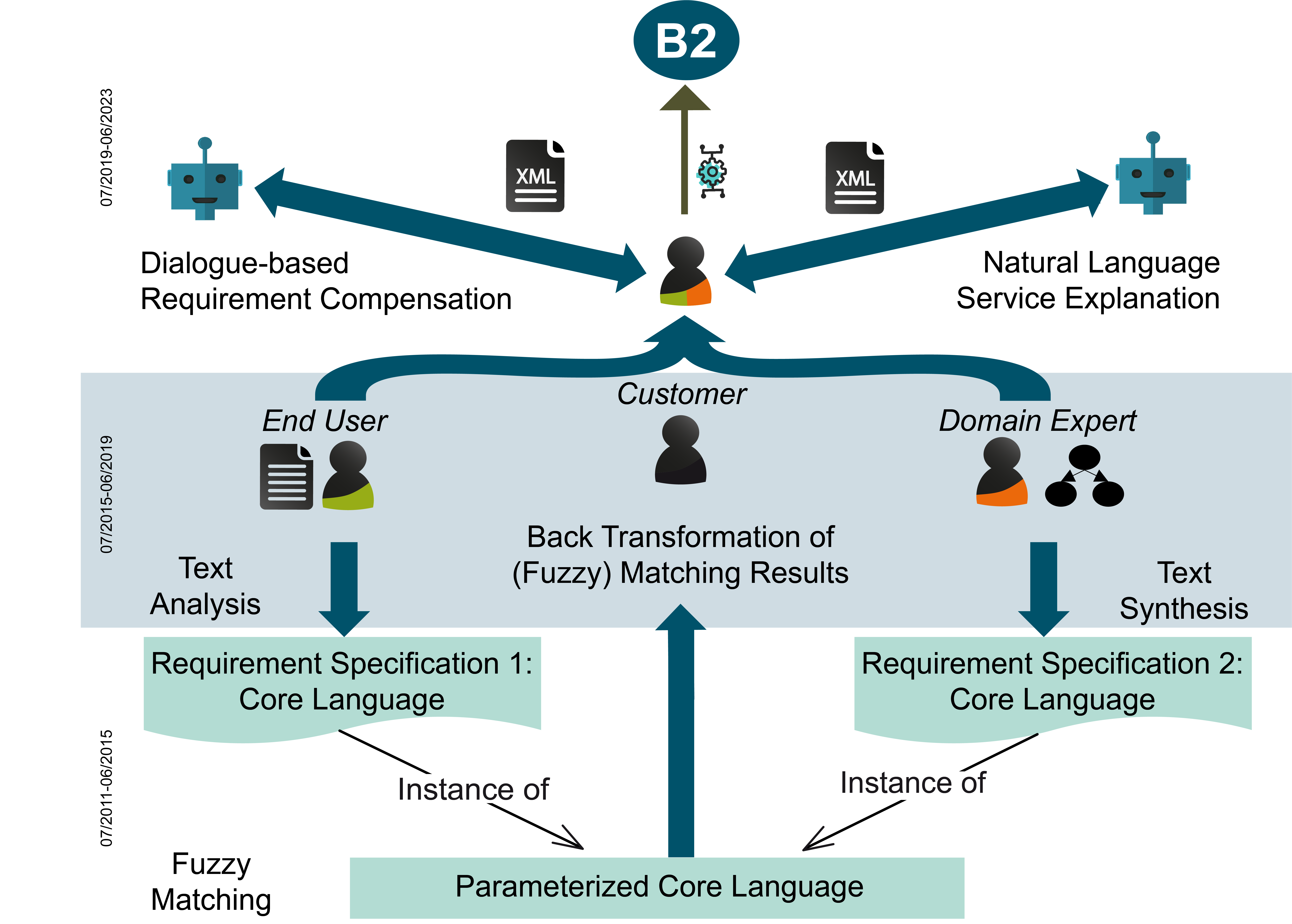
Until June 2015, this subproject focused on customers with technical background, whereas user-friendly service specifications suitable for everyone (with an advanced version for domain experts) were investigated in the following years. Here, we developed a tool for the ”Compensation of Requirement Descriptions Using Linguistic Analysis”, CORDULA. CORDULA empowers users to find software as well as services that can be used to generate canonical core functionalities from service and requirement description texts. CORDULA is further developed during the third phase to address open challenges. So far, CORDULA has a non-optimized execution time and cannot interact with the user. A dialog-based solution is the aim and, thus, CORDULA will be transformed in the next phase.
In the first phase, we concentrated on comprehensive service specifications and automated service matching. In this context, we also developed tool support in the form of a service specification, analysis, and matching environment, called SeSAME. By implementing the core language mentioned in the beginning, SeSAME enables a comprehensive specification of services and considers both functional and non-functional properties. In order to translate specifications created in a different language into the core language, techniques for model transformation “by-example” were developed. SeSAMEs matching tools provide comprehensive processes that can be configured for a given application domain. Furthermore, we support fuzzy matching, which deals with incomplete or inexact specifications.
In the second phase, natural language specifications provided by end users were processed. These specifications were inspired by (English) textual descriptions of apps on service markets such as Google Play. Requirements possibly underspecified by the end user were analyzed automatically (i.e., identified, extracted, classified, and formalized), in order to compensate for ambiguity, vagueness, and incompleteness in the service specifications. Likewise, the “In-House OTF Market” was covered. Domain experts modeled requirements of their companies in the form of examples, which were then automatically synthesized into a comprehensive specification. For this purpose, the synthesis task was translated into an optimization problem, which could resolve existing inconsistencies as well as the (fuzzy) matching of service specifications established in the first phase. Both types of specifications were translated into the core language, in order make them applicable to the defined matching approaches. Detailed matching results were not only important for the customer to interpret them, but also to adapt and refine requirement specifications in case a matching result was not satisfying. As the results were only available in the core language, they had to be translated back into a user-friendly format, which is comprehensible for the above described customers.
The third phase deals with three main issues: First, deficits in the requirement descriptions cannot always be resolved automatically so far. We will approach this issue with a dialog system for the cooperative compensation solution of loss-making templates as a basis for the service configuration. This will be done by developing a domain-specific chatbot-framework for controlling the dialog with respect to the current situation and the user needs. Here, we put the user in the center. The second issue lies in the configuration parameters initially unknown to the users. This issue leads to errors in the templates, which is why we seek to complete the templates with explanations understandable to the users. For this purpose, we plan to employ interactive machine learning in a transparent and context-sensitive way, in order to find and compensate knowledge deficits. The third issue to be faced is that users so far do not know which of their requirements have been fulfilled in a created service and which have not. Thus, the configurated services should be explained and adequately presented. Therefore, we will generate natural language explanations that describe the configuration of the created service in comparison to the service specification at different levels of granularity (from facts to reasons). For generation, we will explore combinations of classic grammar-based and discourse planning methods with state-of-the-art neural sequence-to-sequence models. A key feature of our approach is the adaptation of the explanation style to the language of the user.
Further information: