
Subproject C2
On-The-Fly Compute Centers I: Heterogeneous Execution Environments
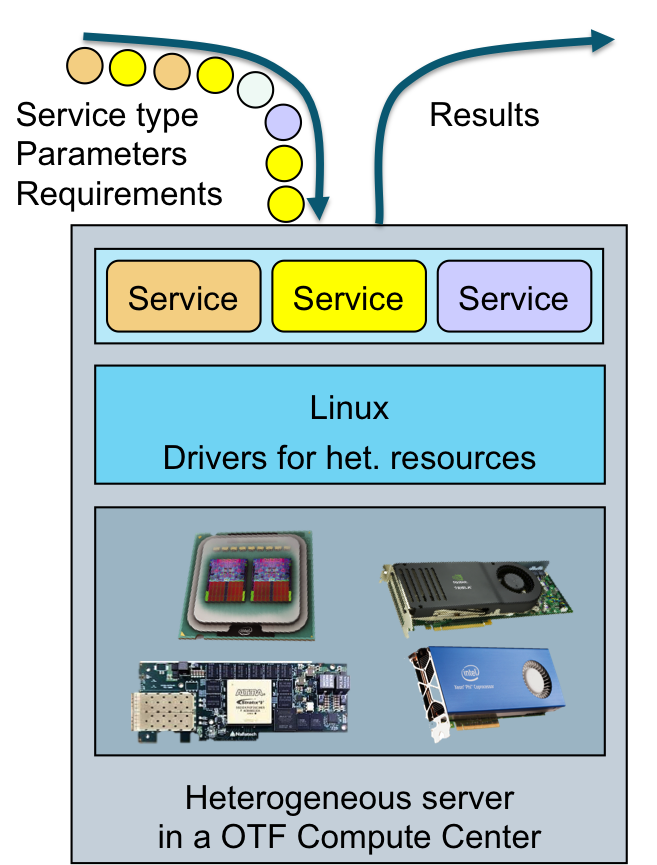
In this project, we investigate the execution of configured IT services in OTF compute centers with heterogeneous compute nodes, which use CPUs, GPUs and FPGAs as compute resources. Such heterogeneous resources are already present and still gaining traction in many installations of compute centers, first adopted in the high-performance computing domain and increasingly expanding into web service and cloud computing domains. For OTF computing to be successful, it must be able to participate in the performance and efficiency gains that are enabled by these heterogeneous compute resources.
OTF computing poses particular challenges for heterogeneous execution through the highly dynamic and variable nature of requests and the demand to establish new service types at runtime. Our approach to deal with the dynamics is to dispatch service invocations to the most suitable heterogeneous resource and also allow for migrating services based on current demand and suitability of resources. This requires executable versions of services for different resources as well as suitable migration mechanisms. The desire to integrate new service types at runtime into the heterogeneous execution environment prompts additional requirements on mechanisms and runtimes of the envisioned solutions.
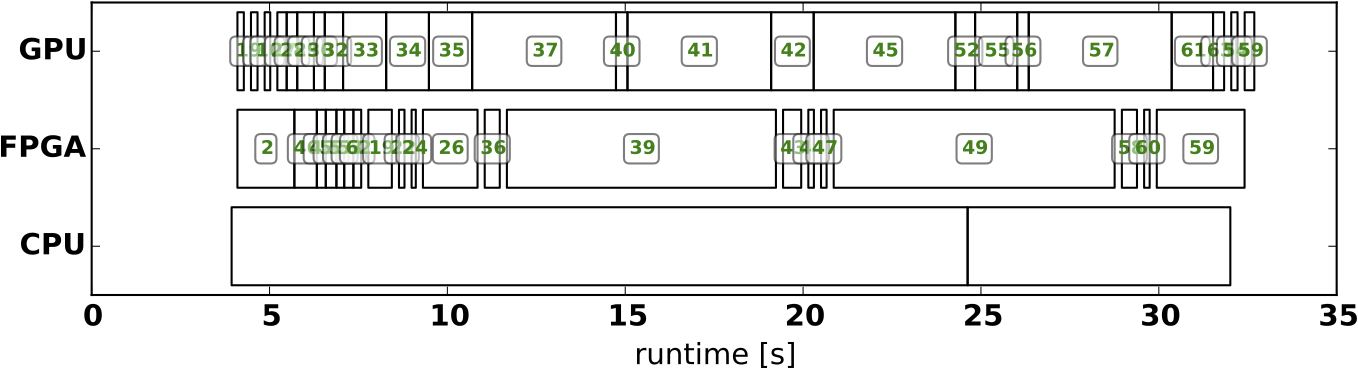
Our research in the second funding period is conducted in two main project areas, firstly in programming for heterogeneity with emphasis on parallelism and migration and secondly in on-the-fly hardware acceleration. Both areas share two common goals for this period, firstly to raise the programmability of heterogeneous compute nodes and secondly to increase the efficiency of the employed methods and tools. In a third, supplemental area, we evaluate the developed methods on a concrete heterogeneous OTF server node, equipped with the heterogeneous compute resources CPU, FPGA and GPU. On this platform, we evaluate heterogeneous scheduling strategies and measure both performance and energy efficiency metrics.
Programming for Heterogeneity: Parallelism and Migration
In this project area, we investigate programming of heterogeneous compute nodes for OTF computing. On the one hand, we investigate and extend suitable programming models, which cover the two major aspects of parallelism and migration or rather migratability. On the other hand, we develop methods for the automatic characterization of non-functional properties of programmed services. The result of this work will be programming tools and characterization methods, that translate and analyze services and service components in a way, that subsequently enables the runtime system to transparently map them to different resources and migrate them between these resources. We believe that this approach can enable efficient utilization of heterogeneous compute nodes even in the context of the highly dynamic OTF context.
After our own previous work, as well as other related work, focused on pthreads as programming model, we now target programming models with a higher degree of abstraction. With those, we hope to achieve progress in two major aspects: we want to reach uniform formalisms that can describe computation on different resource types and we expect that those models can facilitate the automatic detection and extraction of migration points. A higher level of abstraction will lead to limitations in supported application domains, but through increased programmability will improve acceptance for heterogeneous computing nodes. The two programming models we focus on are OpenCL and domain-specific languages. OpenCL is already established as uniform programming model for CPUs and GPUs, support for FPGAs is currently emerging. Thread migration between resources during execution is yet unknown for OpenCL and will be the first subject of our research. As second programming models, we consider domain-specific languages (DSLs) like synchronous data flow (SDF) models, which are used for the application domain of image processing. Those models typically contain more restrictive formalisms than more general languages. We will investigate to which degree such restrictions can facilitate automatic reasoning about suitable migration points and scheduling patterns.
Services and service compositions in OTF computing get annotated with their non-functional properties in order to enable the OTF phases of service discovery, configuration and composition. Scheduling in a heterogeneous OTF compute note also requires knowledge of non-functional properties or at least sufficiently accurate estimates. To that end, in collaboration with project B3, we build upon the models developed there and extend and refine them for heterogeneous resources. For example, execution times and memory demand are of common interest, whereas required buffer sizes and energy consumption are particularly important for heterogeneous migration and scheduling. We consider both off-line characterization, isolated prior to the actual service operation, and on-line characterization, during actual OTF service execution. The latter poses particular challenges through performance and energy related side-effects of load caused by the parallel execution of several services on the compute node. We plan to tackle this challenge with machine learning techniques in cooperation with project B2.
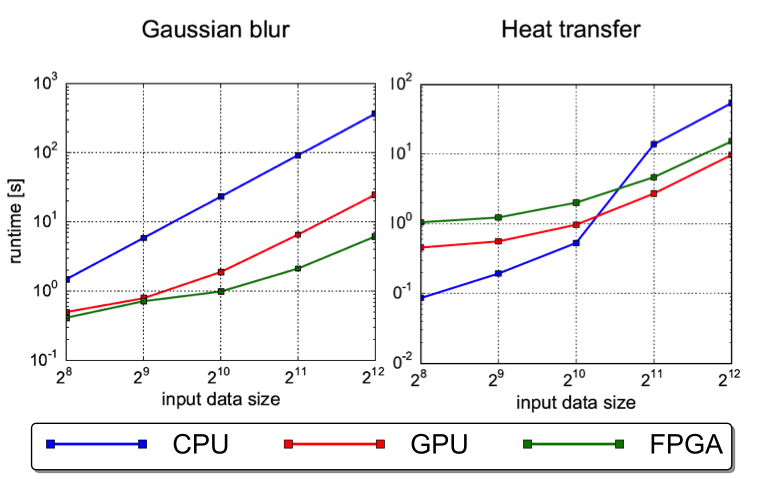
On-the-fly hardware acceleration
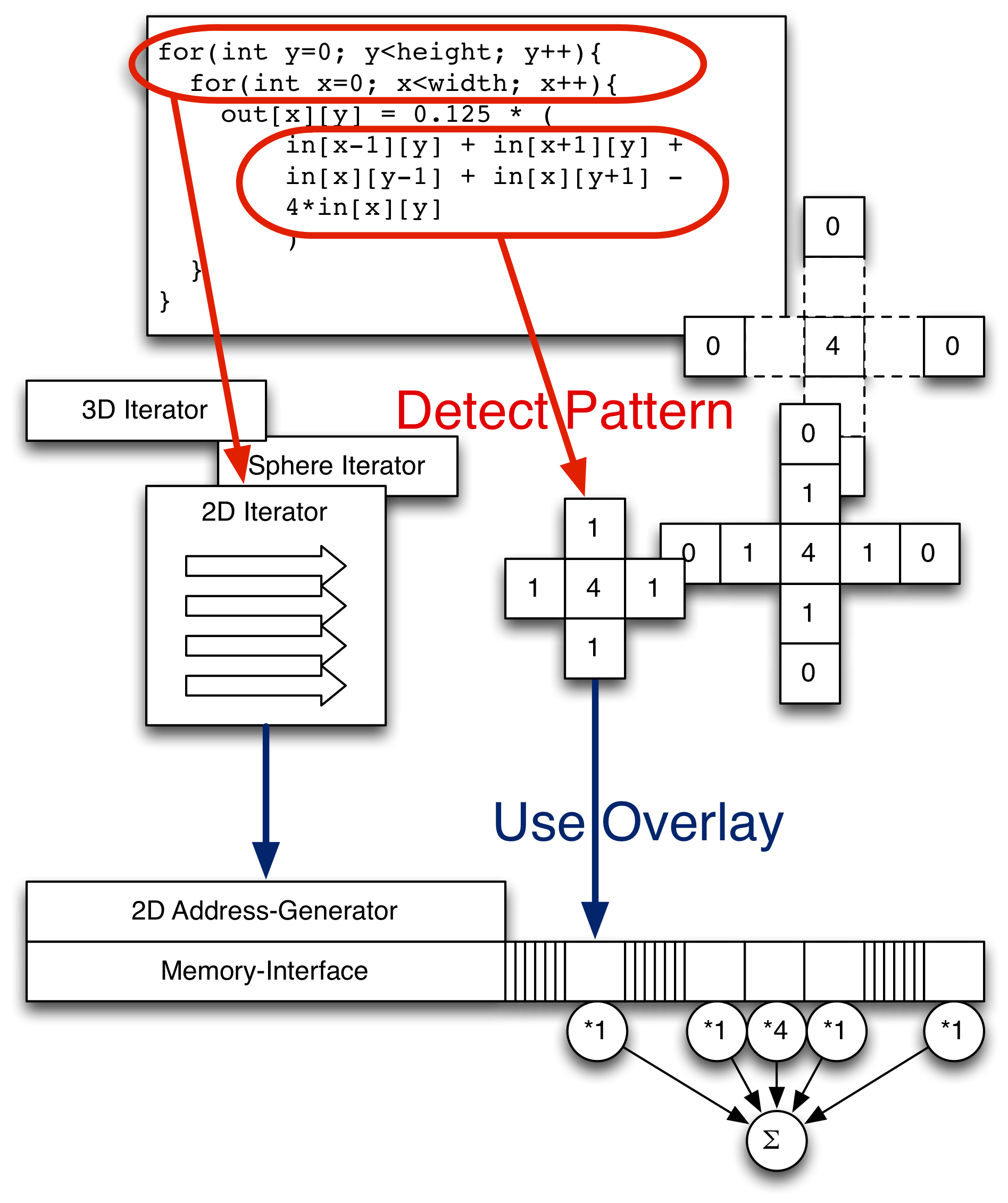
In addition to the work on programming models, we research methods to transparently translate services or parts of services that are only available as binary code for CPU into implementations for reconfigurable hardware (FPGAs). This translation is to take place at service runtime and transparently, that is without manual intervention of a service developer. After this translation process, the generated implementations are made available to the heterogeneous scheduler as alternative, functionally equivalent implementations. Just like implementations obtained with developer interaction through the programming models of the other project area, they can be used to adapt and optimize the heterogeneous system behavior.
One particular challenge for on-the-fly hardware acceleration are the high tool runtimes for the FPGA synthesis process, which can inhibit timely acceleration and conflict with the actual workload of a compute node. We approach this challenge with domain-specific overlays, which can be reconfigured at runtime without repeating the low-level FPGA synthesis process. We are working on methods to select from a set of available overlays a suitable one, to refine an existing overlay architecture by specialization or generalization with re-synthesis for later use, and to generate problem-specific configurations or code for the selected overlay.
A central aspect of this research area are the architectures of such overlays with regard to the specific application domains they are targeting. Overlays can put varying emphasis on exploitation of data parallelism, pipelining or latency hiding through simultaneous multithreading, leading to different architectural approaches. Accordingly, their suitability for different target applications differs a lot. We want to investigate, how a set of overlay architectures can effectively cover a broad range of applications and put a special emphasis on the stress field between specialization of the architecture as prerequisite for high efficiency and the generality of the architecture that is required for good reusability.
The second important aspect in this area are overlay-specific translation methods. On the one hand, each different overlay architecture requires different approaches, but on the other hand, the architectural features of the overlay can guide the detection and translation of suitable application patterns. For this investigation, we consider three overlay architectures. Application-specific reconfigurable vector processors use data parallelism through vector instructions. Customization of instruction formats for specific applications can offer additional efficiency gains. As second target, we consider domain-specific architectures, for example an overlay for finite-difference applications with stencil computations. As third and most ambitious translation target, we consider configurable dataflow architectures. This requires transformation of binary code to a pipelined dataflow representation, for which no established techniques exist yet.
Further information: