
Service Composition Analysis in Partially Unknown Contexts
Subproject B3 of CRC 901
Subproject B3 researches analysis methods for service compositions that evaluate the fulfilments of functional and non-functional requirements. In this, functional requirements might be described by logical pre- and postconditions or protocol specifications; non-functional requirements might concern the runtime or memory consumption, but also the reputation of an assembled composition.
Functional Requirements
Software quality is an important matter in many application areas of modern software engineering. A key to achieve it is the usage of formal analysis. Formal stands for the specification of software using formal models and the analysis of these models using formal methods with respect to certain properties.
In case of service oriented architectures where different services are composed together, those are often need to be assembled or changed on-the-fly. This creates huge challenges to guarantee the desired quality of such composed services. Here ‘quality’ refers to both the functional and non-functional requirements. Analysis of such services must be done within a specified time thereby imposing timing constraints. Different quality assurance method works by transforming a composition into an analysis model which captures the semantics of the service composition. But such techniques are time consuming and difficult to apply in on-the-fly compositional process. The main idea of our work is to use templates which capture the known compositional patterns and verify those using Hoare-style proof calculus to prove their correctness.
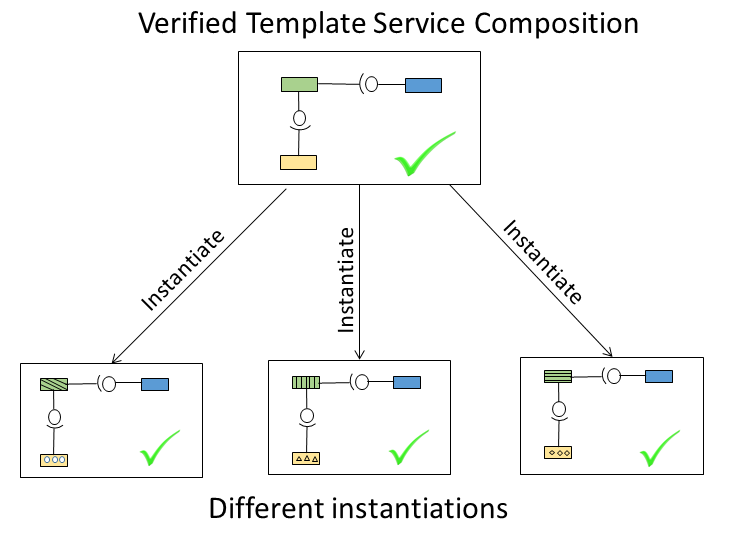
Fig. 1 illustrates our approach. Templates are defined as workflow descriptions with service placeholders, which are replaced by concrete services during instantiation. Every template specification contains pre- and post-conditions which are used to verify the correctness of the templates. Once a template has been proven correct, we only need to prove certain side conditions for the instantiations and can then conclude their correctness.
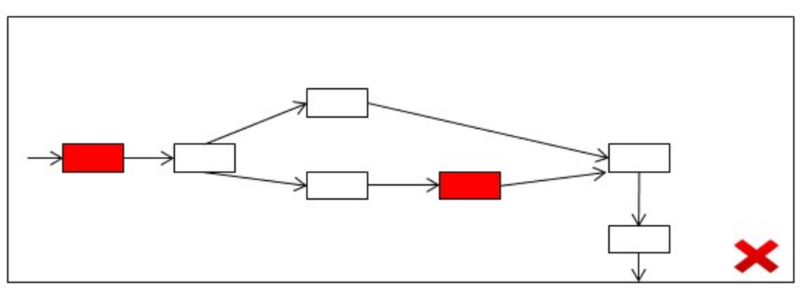
Our work also encompasses localizing the faults in such service compositions. The intention of fault localization is to identify the services most likely causing the fault ( see Fig. 2). To this end, we use a logical encoding of the service composition and it's requirement, and apply a maximum satisfiability solver on it to locate faults.
Non-Functional Requirements
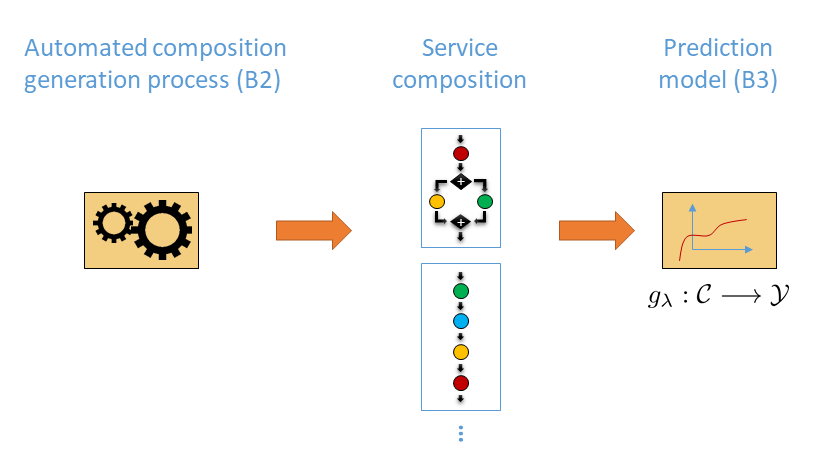
In the second funding period, non-functional requirements of service compositions are analyzed in a data-driven way using machine learning algorithms. The main goal is to predict non-functional properties of compositions, such as runtime, memory consumption, reputation, or reliability, before these compositions are actually executed. In this context, service compositions can be seen as structured objects that are composed on demand by the on-the-fly B2 configurator (Fig. 3). The application of learning algorithms in this scenario comes with at least two major challenges.
First, service compositions are specific types of objects that can vary in size (measured, for instance, by the number of services contained) and structure (e.g., how the services are connected). These objects can not easily be mapped to a feature representation (a vector of constant length) as typically requested by standard machine learning methods. To address this challenge, we develop the "learning-to-aggregate" framework, which is a novel setting of supervised learning. In this setting, we proceed from the assumption that the overall evaluation of a composition is an aggregation of the evaluation of its constituents. Thus, given a set of data in the form of compositions together with their evaluations, an essential part of the learning problem is to figure out the underlying aggregation function. Moreover, since the evaluations of local constituents are normally not observed directly, the problem also involves the "disaggregation" of the overall evaluation, i.e., hypothesizing on the evaluation of individual constituents. For example, in the case of reputation, an OTF user will provide a rating of the whole composition (as a single product), but not to all individual components. The overall rating then depends on how the user evaluates the individual components, and how she aggregates these evaluations into an overall rating (depending on the structure of the composition). The learning-to-aggregate approach seeks to answer both questions simultaneously [1].
The second challenge arises from the configuration process as realized by subproject B2. To satisfy the request of an OTF user, service compositions are build in an on-the-fly manner. In this regard, the task of the configurator is not only to satisfy the functional properties (i.e., to solve the task correctly), but also to find a service composition that is optimal in terms of certain non-functional properties. For instance, a user might want to have a composition with the lowest runtime. To efficiently guide the search in the huge space of possible configurations, the configurator should be able to estimate the required non-functional properties of compositions efficiently. In particular, such as estimate should be possible for partially specified configurations. We refer to such requests as "range queries", since partial service compositions can be associated with a range in the "space" of complete compositions. The sought prediction is not a single value, but rather a set of values, namely the values of all complete compositions within the range. Again, learning range-query predictors from data is an interesting problem from a machine learning point of view.
Ongoing work
In the current funding period, the goal of the subproject B3 is to address these major challenges, and to develop and analyze learning methods that can be successfully applied in the described scenarios. In cooperation with subproject B2, we elaborate on automated machine learning (AutoML) as a suitable case study. In this context, the learning-to-aggregate problem consists of predicting a non-functional property (e.g., predictive accuracy) for so-called machine learning pipelines consisting of modules for data pre-processing, classifier learning, etc. On the functional side, these pipelines have several interesting properties. For instance, we can check whether the training data is used in a balanced way during learning process. Moreover, range queries are relevant in connection with the tuning of hyper-parameters, i.e., the problem of optimizing the parameters of the methods in a pipeline.
Further Information
For further information about, please consult our publications or contact our researchers and have a look at our previous work.
Further information: