TiLe
TiLe is a framework which can be used to test the balancedness of machine learning (ML) classifiers. Here ‘balancedness’ means, whether a ML classifier is using the entire training data in its training phase in a similar manner or not.
Approach
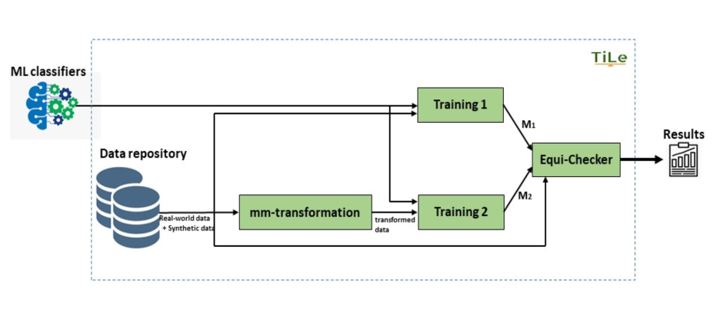
The framework consists of a Data repository which is a collection of real-world data collected from UCI machine learning repository and synthetic data which we have generated, different metamorphic- (mm-) transformation functions (applying permutations on the training data) and an efficient Equivalence checker to check the equivalence between two models (classifiers) after the training phase. Fig.1 depicts the overall workflow of our approach. To check for balanced data usage of any ML classifier, TiLe takes as input the classifier and trains it with data from the Data repository. It then applies different metamorphic transformation functions on the data of the repository and use this transformed data to re-train the classifier. These two different training (Training 1 & Training 2) phases generate two models M1 and M2. Then equivalence checking is performed to find out, whether the two models are different or the same. We have evaluated TiLe on different state of the art classifiers and also some classifiers which are potentially by design unbalanced.